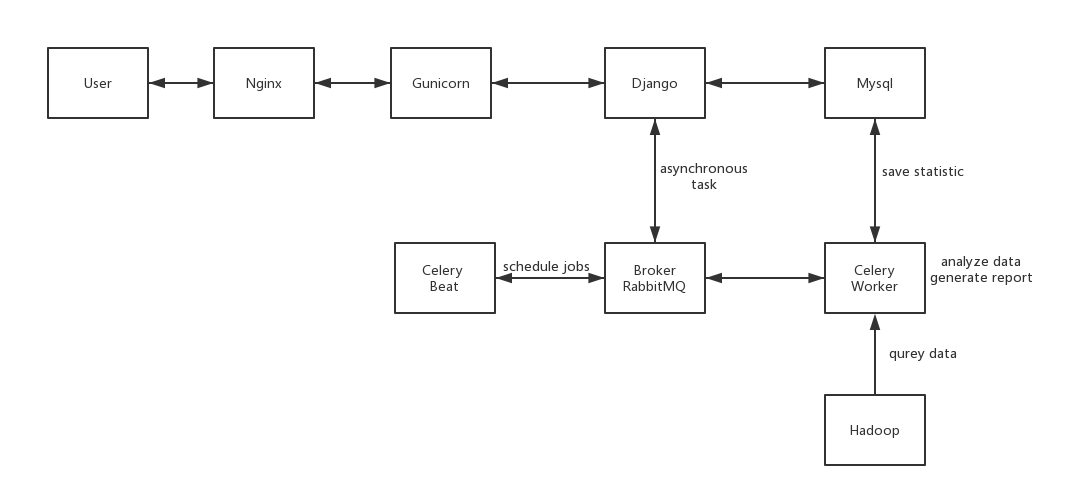
对于编程初学者,如果有一个开箱即用的环境,比如web页面,就可以进行编程交互,那是极友好。有时候我们想在远程服务器上执行一些脚本,输出一些结果,比如科学计算;有时候又想在服务器上执行一些命令但又不能直接登录服务器,如果能够在web界面上操作或作为跳板机,那也是极友好的。Jupyter Notebook是基于IPython的一个基于web交互执行的在线环境,支持Python,也支持其他编程语言,比如Julia和R。所创建Notebook文档可以自动保存执行过的代码、结果,方便进行回放。
Jupyter Notebok的安装很方便,可以使用Anaconda来安装,或者手动安装。Python3下手动安装,
pip3 install jupyter export PATH=$PATH:/usr/local/python3/bin
查看一下
[root@localhost local]# pip3 show jupyter Name: jupyter Version: 1.0.0 Summary: Jupyter metapackage. Install all the Jupyter components in one go. Home-page: http://jupyter.org Author: Jupyter Development Team Author-email: [email protected] License: BSD Location: /usr/local/python3/lib/python3.7/site-packages Requires: jupyter-console, notebook, ipywidgets, nbconvert, qtconsole, ipykernel Required-by:
如果直接运行jupyter notebook,那么会生成一个本地可以访问的带token的url,每次都不一样,不是很方便。设置密码,以便登录
[root@localhost opt]# jupyter notebook password
Enter password:
Verify password:
[NotebookPasswordApp] Wrote hashed password to /root/.jupyter/jupyter_notebook_config.json
[root@localhost bin]# cat /root/.jupyter/jupyter_notebook_config.json
{
"NotebookApp": {
"password": "sha1:e04153005102:961b12eef91987a06b497f915fc3f18c62d8f714"
}
由于是在虚拟机里面,我们并不需要Jupyter自动打开浏览器,但需要监听来自任意IP的请求,指定端口9030。这里使用root用户运行Jupyter,默认是不允许的:
[root@localhost opt]# jupyter notebook --no-browser --allow-root --ip 0.0.0.0 --port 9030
[I 02:13:44.320 NotebookApp] Serving notebooks from local directory: /opt
[I 02:13:44.320 NotebookApp] The Jupyter Notebook is running at:
[I 02:13:44.320 NotebookApp] http://(localhost.localdomain or 127.0.0.1):9030/
[I 02:13:44.320 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[I 02:13:59.664 NotebookApp] 302 GET / (192.168.33.1) 1.22ms
[I 02:14:23.597 NotebookApp] Kernel started: 7ad63717-7a65-4dec-9d5a-9af654c28f75
[I 02:14:25.204 NotebookApp] Adapting to protocol v5.1 for kernel 7ad63717-7a65-4dec-9d5a-9af654c28f75
[I 02:14:37.350 NotebookApp] Starting buffering for 7ad63717-7a65-4dec-9d5a-9af654c28f75:ea68853b742c40f8bcf8745529ea95de
[I 02:14:43.735 NotebookApp] Kernel started: 5b569c8d-6936-4bd2-9674-0317c46948f6
[I 02:14:44.124 NotebookApp] Adapting to protocol v5.0 for kernel 5b569c8d-6936-4bd2-9674-0317c46948f6
[2019-06-03 02:14:43] kernel.DEBUG: Connection settings {"processId":6751,"connSettings":{"shell_port":39990,"iopub_port":48184,"stdin_port":40113,"control_port":43426,"hb_port":49075,"ip":"127.0.0.1","key":"d5f89bba-890ecf15e6b20718411170ad","transport":"tcp","signature_scheme":"hmac-sha256","kernel_name":"jupyter-php"},"connUris":{"stdin":"tcp://127.0.0.1:40113","control":"tcp://127.0.0.1:43426","hb":"tcp://127.0.0.1:49075","shell":"tcp://127.0.0.1:39990","iopub":"tcp://127.0.0.1:48184"}} []
[2019-06-03 02:14:44] KernelCore.DEBUG: Initialized sockets {"processId":6751} []
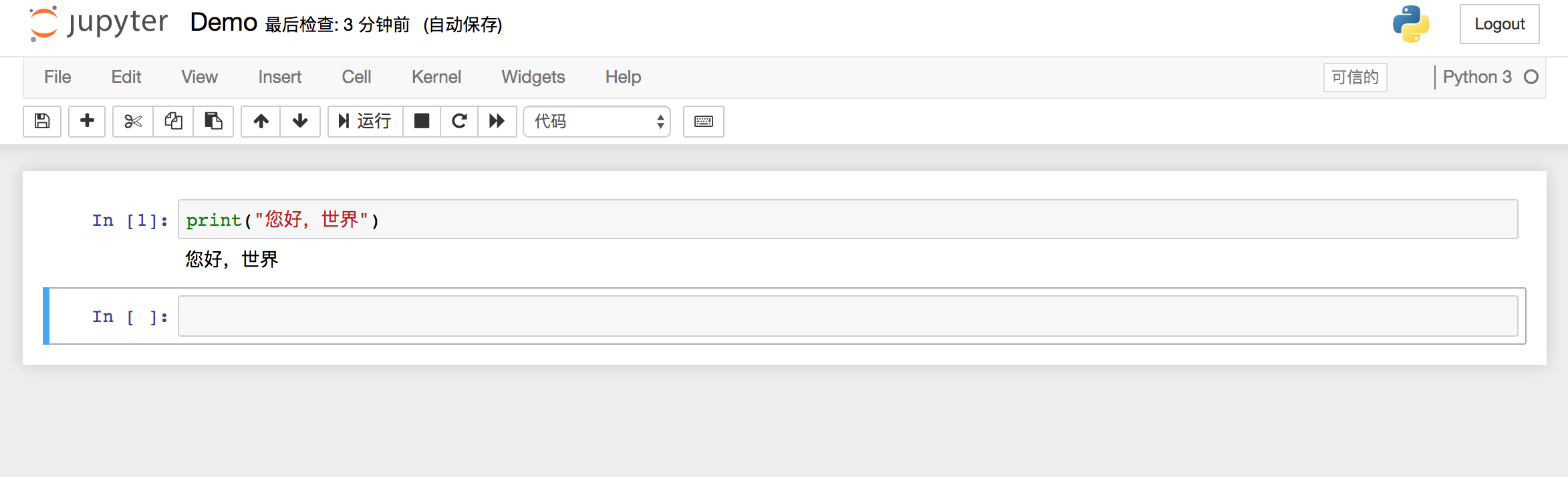
然后打开浏览器,访问http://192.168.33.70:9030,输入账号密码,就可以在web里面运行Python了
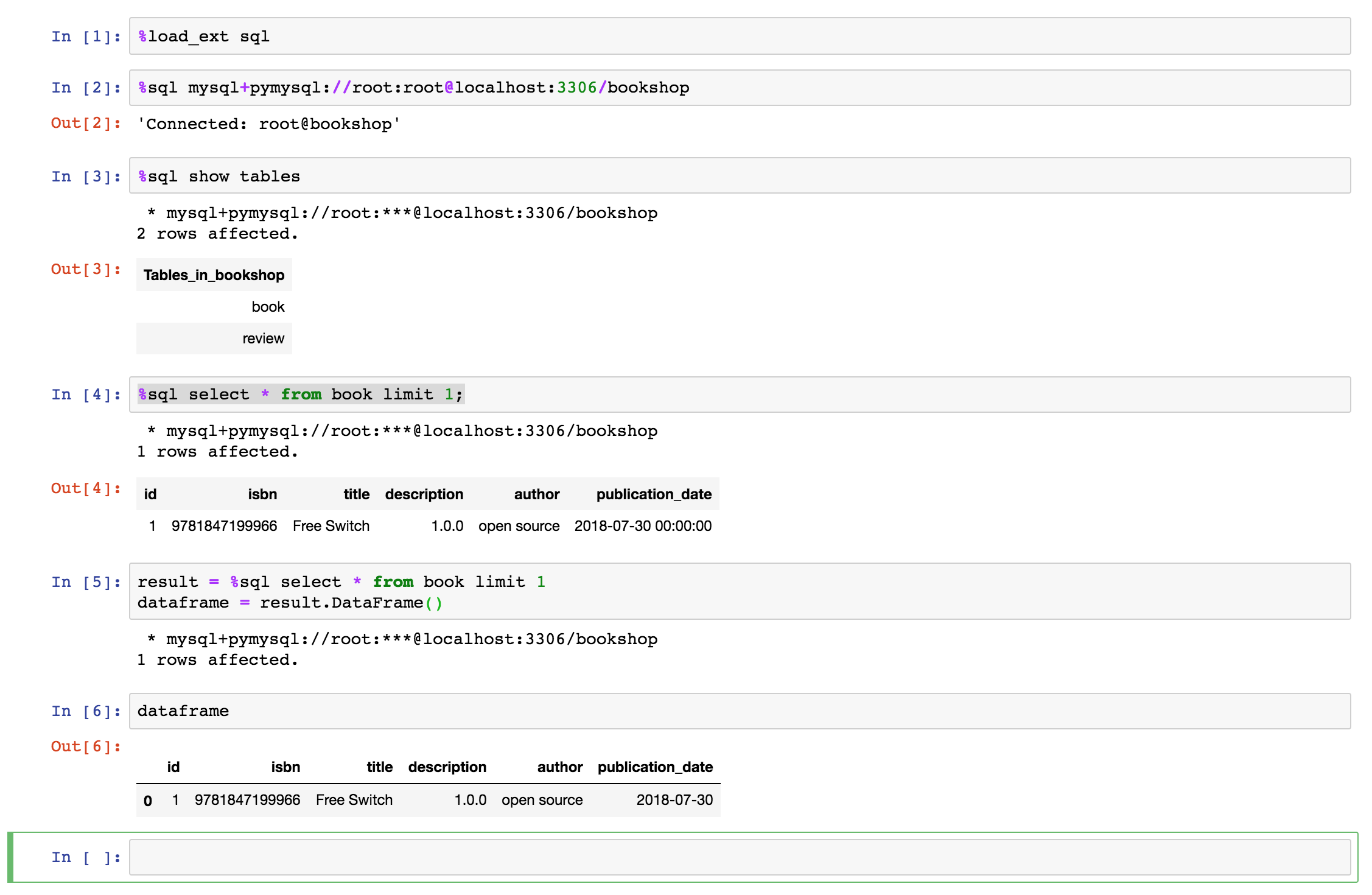
Jupyter默认带了SQL扩展,使用ipython-sql来执行,只需要安装对应的驱动,这里使用PyMySQL
python3 -m pip install PyMySQL
然后在Web里面执行就可以了
Jupyter还有其他扩展,参考这里。
除了可以执行Python和SQL,Jupyter Notebook也可以支持其他语言,在这里列出了。通常执行方式是通过Bash执行,或者通过ZeroMQ来通信,参考这里实现。一个Jupyter的kernal将需要监听以下几个socket:
这个思路也可以用来做IOT设备的远程监控,交互执行。
这里安装一下PHP 7这个kernel,作者甚至还提供了installer,但是首先要安装ZeroMQ以便与Jupyter服务通信
yum install php-pecl-zmq wget https://litipk.github.io/Jupyter-PHP-Installer/dist/jupyter-php-installer.phar ./jupyter-php-installer.phar install
查看安装文件
[root@localhost opt]# ls -la /usr/local/share/jupyter/kernels/
total 0
drwxr-xr-x. 4 root root 34 May 10 06:10 .
drwxr-xr-x. 3 root root 20 May 9 07:30 ..
drwxr-xr-x. 2 root root 24 May 9 07:30 jupyter-php
drwxr-xr-x. 2 root root 40 May 10 06:10 lgo
[root@localhost opt]# cat /usr/local/share/jupyter/kernels/jupyter-php/kernel.json
{"argv":["php","\/opt\/jupyter-php\/pkgs\/vendor\/litipk\/jupyter-php\/src\/kernel.php","{connection_file}"],"display_name":"PHP","language":"php","env":{}}
这个扩展使用了react/zmq来监听Jupyter请求,使用psysh来交互执行PHP代码。

如果想要更改Jupyter的web模板,可以在以下目录找到
[root@localhost vagrant]# ls -la /usr/local/python3/lib/python3.7/site-packages/notebook/templates total 92 drwxr-xr-x. 2 root root 4096 May 9 06:33 . drwxr-xr-x. 19 root root 4096 May 9 06:33 .. -rw-r--r--. 1 root root 147 May 9 06:33 404.html -rw-r--r--. 1 root root 499 May 9 06:33 browser-open.html -rw-r--r--. 1 root root 4258 May 9 06:33 edit.html -rw-r--r--. 1 root root 856 May 9 06:33 error.html -rw-r--r--. 1 root root 4256 May 9 06:33 login.html -rw-r--r--. 1 root root 1179 May 9 06:33 logout.html -rw-r--r--. 1 root root 23162 May 9 06:33 notebook.html -rw-r--r--. 1 root root 6559 May 9 06:33 page.html -rw-r--r--. 1 root root 1089 May 9 06:33 terminal.html -rw-r--r--. 1 root root 12130 May 9 06:33 tree.html -rw-r--r--. 1 root root 544 May 9 06:33 view.html
Jupyter Notebook Web前端采用WebSocket与服务器交互,服务器接收消息并转发给对应的kernel执行或控制,并将结果推送给前端。Jupyter Notebook也可以直接打开Terminal,在远程服务器上执行命令。注意这里的用户就是刚才运行jupyter的用户
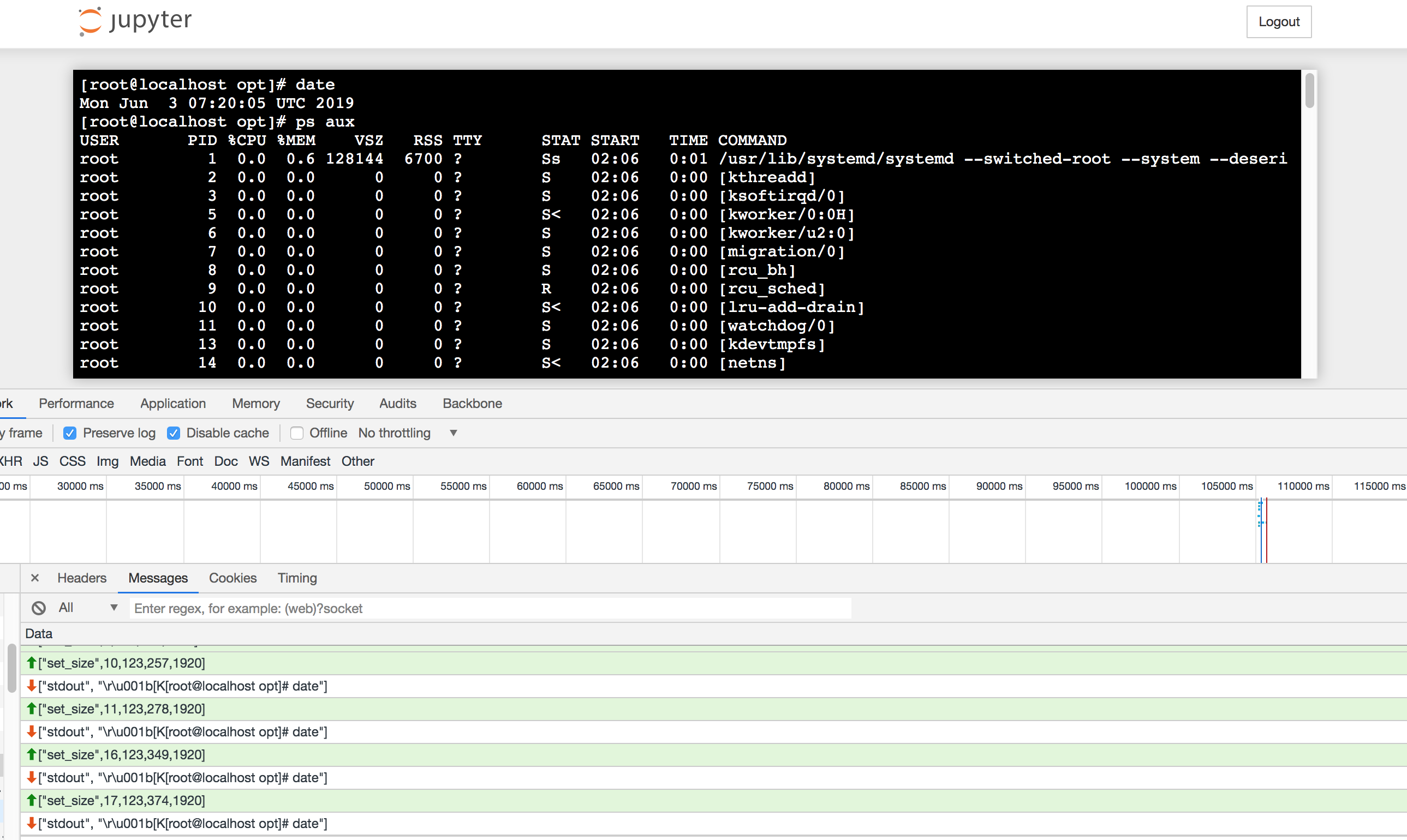
许多web terminal也都是采用WebSocket来做交互,比如xterm.js,webtty。
Juypter Notebook适合单用户(单机)使用,如果提供多用户使用(比如教学),可以使用Jupyter Hub,可以使用docker快捷部署。
参考链接:
Jupyter Notebook Extensions
Jupyter – How do I decide which packages I need?
PsySH——PHP交互式控制台
Jupyter项目
WebSocket 教程